Self-paced course taken summer ‘22, linked here. Introductory data science programming using Python — teaches Python basics, programming fundamentals, and data science modules in Python. Texts used include Allen B. Downey’s Think Python, 2nd Edition and Al Sweigart’s Automate the Boring Stuff. Completed homework linked here.
control flow
introduction
- inputs: keyboard, mouse
- outputs: monitor, speaker
- devices attach to the computer via “ports” (USB)
- motherboard: main circuit and connects to other components with sockets and slots
- CPU, central processing unit
- runs code (receives input, sends output)
- runs on a clock, measured in Hz (ex. GHz is billions of ticks per second)
- high speed CPU → hotter
- computers have multiple CPUs
- RAM, random access memory
- short term data storage
- CPU sends to and from RAM
- “volatile” - lose data when computer is powered off
- one byte = one letter
- short term data storage
- storage drives
- HDD, hard disk drive
- inexpensive, moving parts, slow
- SSD, solid state drive
- expensive, no moving parts, fast
- stores data after computer shut down
- HDD, hard disk drive
- network: an extension or built-in card to the motherboard
- NIC, network interface controller
- provides communication to other machines + internet
- wired = ethernet, wireless = wifi
- server: computer waits for incoming requests which it responds to
- client: program that sends requests to a server
- NIC, network interface controller
- jupyter notebook runs and displays results of py code without needing to run it yourself
the terminal
- you can connect to terminals located anywhere, such as connecting to a remote computer OR connecting to a personal computer
- shell helps navigate to program and run
- helpful shell commands
pwdget working directory → current locationmanopens manual pages for command<tab>autocomplete<ctrl-C>kill / exit<up arrow>last used command<ctrl-R>search used commandscdopen directorycd ..go up a directorycd /go to top directory
lslists contents of current directorymkdirmakes new directoryechorepeat or copycatdisplay contents of filemv [original] [destination]move filescp [original] [destination]copy files
- pathname: the location of your file (windows: includes drive letter, filename, extension…)
- absolute: always possible (complete path name to file)
- relative: with respect to current location
- working directory: current location
..navigates up a directory.navigates into a directory
- arguments are inputs that come after the call of the program name
- use
>to redirect output to a new file - use
>>to add output to a file
programming
- interpreter: a program that translates human-legible code into machine-legible code
- editor: a program where you can write code
- jupyter notebook mixes code with other things like images, tables, documentation, etc
- ways to run python
pythoninteractive, denoted by>>>python [program name]scriptjupyter notebooknotebook
- python uses order of operations to simplify equations (parentheses, exponents, m/d, a/s)
- negative and positive signs take precedence over m/d
- logic operators come after comparison operators which come after math operators

- boolean operators
- AND: true when both conditions are true (t/t), false otherwise (t/f, f/t, f/f)
- OR: true when one condition is true (t/t, t/f, f/t), false otherwise (f/f)
- NOT: true when the condition is false
- evaluate: NOT(is it saturday?)
- if (is it saturday?) is true, then the expression is false, i.e., it IS saturday
- if (is it saturday?) is false, then the expression is true, i.e., it is NOT saturday
- evaluate: NOT(is it saturday?)
downey ch1: the way of the program
- python uses symbols as bitwise operators and words as logic operators
andorare logic operators&|are bitwise operators- convert arguments into binary before comparisons
- common types: int, float, string, boolean
- parsing is understanding structure and meaning in a language
- formal language: specifically designed languages (like mathematical or molecular notation); means exactly what it says, unambiguous, less redundant/more concise
- natural language: naturally-evolved language (like English); has idioms/metaphor, needs redundancy to make up for ambiguity
variables and expressions
- expressions are a mix of operators (logic, mathematical) and operands (values)
- an operand could be a variable which means it won’t be a fixed value
//is the floor division operator:x // yis “how many times doesygo intox?
- assignments compute an expression and put the result in a variable — assignment operator is
=- ex:
total = x+ywheretotalis the resultant variable;xandyare operands (and also variables);x+yis the expression
- ex:
- types of errors
- syntax error: the written code is wrong, Python won’t run, ex:
5 = x, we can’t assignxto the number5 - runtime errors: something that crashes when we run the code, ex:
x = 5 / 0, can’t divide by zero and will result in aZeroDivisionError - semantic (logic) error: the code runs but you don’t get the result you want
- syntax error: the written code is wrong, Python won’t run, ex:
- python variable naming conventions
- don’t use keywords
False assert del for in or while None break elif from is pass with True class else global lambda raise yield and continue except if nonlocal return as def finally import not try - don’t name your variable after a type, like
intorstr - only use letters (upper + lower), numbers, underscores
- don’t start the variable name with a number
examples nonexamples CS220 220class cs_220 x! _cs220 pi3.14 - don’t use keywords
downey ch2: variables, expressions and statements
- python conventionally uses lowercase and underscores for variable names
- illegal names will cause syntax errors
- python code can be saved into files called scripts which end with
.py print()needs to be used in script mode if you want to display outputs- PEMDAS is helpful for remembering the order of operation for expressions
- Parentheses, Exponents, Multiplication and Division, Addition and Subtraction
- can’t perform mathematical operations on strings but we can add strings together (called string concatenation)
first = 'throat' second = 'warbler' print(first + second) > throatwarbler - strings can also be multiplied, ex:
'Spam'*3is'SpamSpamSpam' - comments are lines that the computer will ignore — used to make notes between lines of code for humans to read
# compute percentage of an hour percentage = (minute * 100) / 60- everything on the line with the
#symbol is ignored - usually used to denote things that aren’t obvious to the reader — meanings of variables, functions
- everything on the line with the
- syntax errors appear before the program is run; runtime errors appear after the program has run; semantic errors don’t appear at all
using functions
- functions are “mini-programs” or small steps that can build a big program
- refactoring is when the code is reorganized
- parameters are variables that receive a function’s input
- arguments are values that are sent to a function
- default arguments are values that are sent to the function if no custom value is provided
- return values are outputs from the function
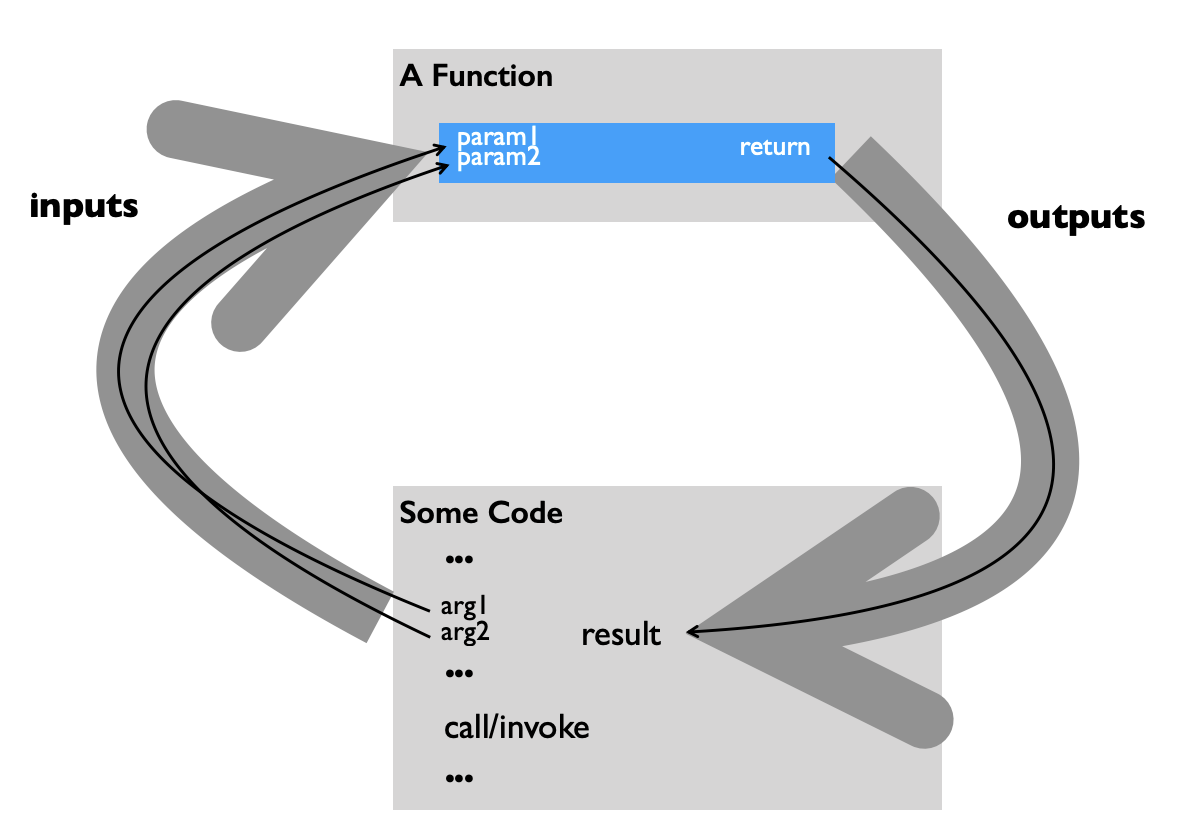
- calling a function in python:
[fnc name]([arguments])ex:print("hello")whereprintis the function name, followed by parentheses, and"hello"is the argument
downey ch3: functions
- function - a named sequence that performs a computation
- python has modules which are prewritten code that you can use in your program by importing
- ex: functions from the math module can be used after importing it with
import math, includingmath.sin(),math.log10(), etc
- ex: functions from the math module can be used after importing it with
- functions can be called using dot notation which is the format
[module name].[function name] - variables are always on the left side of an assignment operator
creating functions
- math to python example
def f(x): return x ** 2- both functions are called
fand take a parameter,x, and return the value ofxsquared
- both functions are called
- indentation is important in python!
- following the colon after the first line of a function, all following lines are indented 4 spaces
- filling parameters
- positional arguments — arguments assigned by position
def foo(x, y = -1): x = [] # this would be 99, because 99 is the first arg y = [] # this would be 100 foo(99, 100) - keyword arguments — arguments assigned to variable names
def foo(x, y = -1): x = [] # this would be 100 because we said x=100 below y = [] # this would be 99 foo(y=99, x=100) - default arguments — inserted arguments if nothing is provided
def foo(x, y = -1): x = [] # this would be 99 y = [] # this would be -1 because we specified it above foo(99)
- positional arguments — arguments assigned by position
returnwill provide code to the program that can be used later, whileprint()will output the code to a terminal
downey ch3 (cont.): functions
- custom functions can be added by using the keyword
def- the header of the function is the first line, while the body **(indented 4 spaces) is the rest of the function
- if the parentheses after the function name are empty, that means the function doesn’t take any arguments
def foo(): print(36) foo() > 36 - functions have to be created before they can be called → function definitions are always at the top of a program
- execution begins at the top of the program and moves down
- fruitful functions return values; void functions don’t return anything
- usually want to perform an action with the output of a fruitful function
reading: creating fruitful functions
- to send a value to a variable instead of printing it to a screen, we can use the
returnkeyword → is called a fruitful function- result is stored in a variable and can be used again
# using print def get_name(first, last): print(first + " " + last) name = get_name("Jane", "Doe") > "Jane Doe" print(name) > None # nothing is assigned to 'name' so it has the None type# using return def get_name(first, last): return(first + " " + last) name = get_name("Jane", "Doe") # nothing prints because there is no print statement print(name) > "Jane Doe" # the name is returned through the function - once a
returnstatement is reached, the function ends# using print() def countdown_print(): print(3) print(2) print(1) countdown_print() > 3 > 2 > 1# using return def countdown_return(): return 3 return 2 return 1 countdown_return() > 3 __builtins__is a special module that is already importeddir()lists all functions that are part of a module.__doc__returns the documentation of a functionimport math print(math.log.__doc__) # [module name].[function name].__doc__ > log(x, [base=math.e]) > Return the logarithm of x to the given value
function scope
- variable names can be organized in frames
- frames are created when a function is called — parameters and variables exist in the frame (also called scope?)
def print_twice(s): # function frame print(s) print(s) def cat_twice(p1, p2): # different function frame cat = p1 + p2 print_twice(cat) line1 = "bing bong" # lies in the global frame line2 = "bong bing" # lies in the global frame cat_twice(line1, line2)- the module can access two variables:
line1andline2 cat_twice()accesses three variables:p1(which isline1passed through the function),p2(which isline2passed through the function), andcatprint_twice()only accesses one variable:swhich iscatpassed through
- the module can access two variables:
- local variables
- functions don’t execute unless they’re called
def set_x(): x = 100 print(x) # doesn't print anything because set_x() wasn't called - variables created in a function die after the function returns
def set_x(): x = 100 set_x() print(x) # doesn't print because x doesn't exist after the end of the function - variables are reset every time a function is called
- variables aren’t shared across functions
def display(): print(x) def main(): x = 100 display() main()- even though
xis set to be100in themain()function, thedisplay()function can’t see thexvalue and it doesn’t print anything
- even though
- functions don’t execute unless they’re called
- global variables can be used inside functions
- python assumes any variables assigned within functions are local variables
msg = "hello" def greeting(): msg = "welcome!" # local variable, only present within the function print("greeting: " + msg) print("before: " + msg) greeting() print("after: " + msg) > before: hello > greeting: welcome! > after: hello
- python assumes any variables assigned within functions are local variables
- use
global [var name]to declare when to create a global variablemsg = "hello" def greeting(): global msgd msg = "welcome!" # local variable, only present within the function print("greeting: " + msg) print("before: " + msg) greeting() print("after: " + msg) > before: hello > greeting: welcome! > after: welcome! - python arguments are “passed by value” meaning any change to an argument that happens inside a function does not apply to that variable outside of the function
- the argument and parameter can have the same (or different) name
downey ch3 (cont.): functions
- inside a function, arguments are assigned to variables called parameters
- variables created inside functions exist only in that function
- a traceback is a list of functions that details what file, line, and functions caused an error
- usefulness of functions
- repetitive code can be named and grouped, which makes debugging easier
- reusuable
- Linux started out as a program that would switch between printing
AAAAandBBBB
conditionals
- statements are always executed in order, with three exceptions: functions, conditionals, and loops
- indented lines = “inside” functions
- questions are often phrased as boolean expressions, while actions are written as statements
- control flow diagrams are flowcharts for code — visual representation of how the code should run
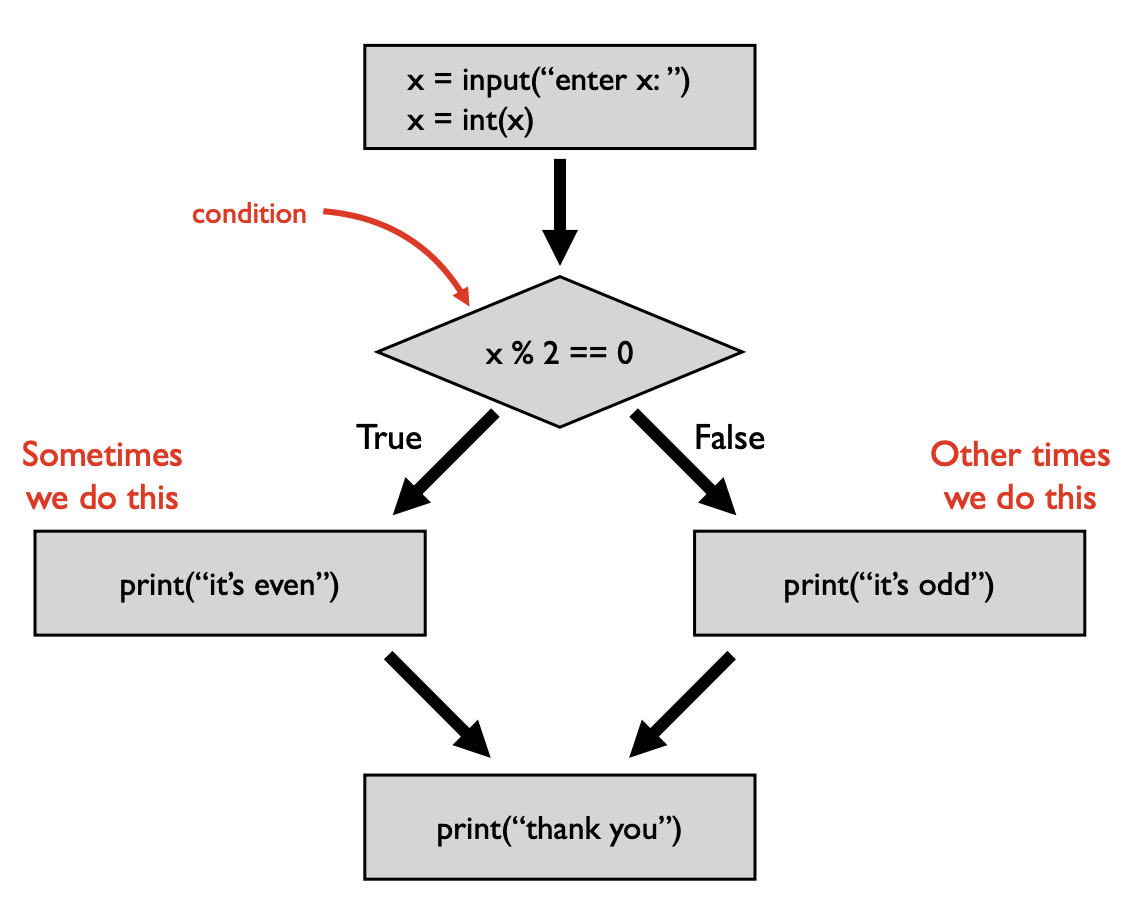
- a boolean expression uses the
ifkeyword and sometimes useselseif there are multiple solutionsif [boolean expression == True]: # execute code else: # implying that boolean expression == False # execute different code - blocks of code are defined by indentations (which come with colons)
downey ch4: case study: interface design
- the
turtlemodule in python allows you to create images with turtle graphics- basically, it’s a little “turtle” that you can control using commands (move forward, turn left) to draw stuff
forloops can be used to repeat pieces of codefor i in range(4): print(i + "hello!") > 0 hello! > 1 hello! > 2 hello! > 3 hello!- the
iis a counter variable — starting at 0, it will increase by 1 every loop 4is the number of times the loop will repeat
- the
- encapsulation is when you wrap up code in a function
- this gives the code a name, which serves as documentation (noting what its purpose is)
- generalization is adding parameters to a function to make it more “customizable”, ex: creating a function that draws a square of any size instead of just 1 size
- the interface of a function is a summary of how the function is used, including parameters, purpose, return values
- a good interface achieves its purpose without needing to provide unnecessary information
- refactoring is the process of rearranging a program to improve interfaces — the goal is to make the code more readable and still be useful
- docstrings are strings at the top of a function that explains the interface (basically describes the purpose of the function)
- doc = documentation
- also called headers or javadoc comments in Java
- all docstrings are triple-quoted
def polyline(t, n, length, angle): """Draws n line segments with the given length and angle (in degrees) between them. t is a turtle.""" for i in rage(n): t.fd(length) t.lt(angle) - preconditions are things that are required to be true before the start of a function, ex: the
angleparameter has to be a positive value - postconditions are conditions at the end of the function
- if the postconditions are wrong but the preconditions are satisfied, then the bug is within the function
downey ch5: conditionals and recursion
- the floor division operator (
//) divides two numbers and returns the integer (rounds down), ex:5 // 3 = 1 - the modulus operator (
%) divides two numbers and returns the remainder, ex:5 % 3 = 2 - a boolean expression will evaluate to either
TrueorFalseand uses the==operator!=not equal to>greater than<less than>=greater than or equal to<=less than or equal to
- logical operators:
andornot ifstatements are conditional statements, which check conditionsif x > 0: print("x is positive")- if there is more than one possibility of the conditional statement,
elseclauses can be addedif x > 0: print("x is positive") else: print("x is negative") - if there are more than two possibilities, use
elifto define other conditionsif x > 0: print("x is positive") elif x < 0: print("x is negative") else: print("x is 0")
- if there is more than one possibility of the conditional statement,
- conditionals can also be nested inside each other — the next example is a re-write of the previous one
if x > 0: print("x is positive") else: if x < 0: print("x is negative") else: print("x is 0")
downey ch6: fruitful functions
- return values are usually assigned to variables or used in an expression
- if conditional statements are used, there can be multiple return statements — it’s good practice to make sure the program can return a value no matter which path it takes
- code that appears after a return statement is called dead code because it will never be executed
- incremental development is the process of adding and debugging code in small chunks as to avoid long/complicated debugging sessions
- comments or tester pieces of code are called scaffolding which can be helpful for debugging, but aren’t part of the final product
- start with a working program and make small changes
- display intermediate values
- remove scaffolding to make code easier to read
- one function can be called from within another
- functions can return booleans
- common for the function name to be a yes/no question, like
is_even(),is_raining(), oris_divisible()
- common for the function name to be a yes/no question, like
iteration
- control flow diagram for a
whileloop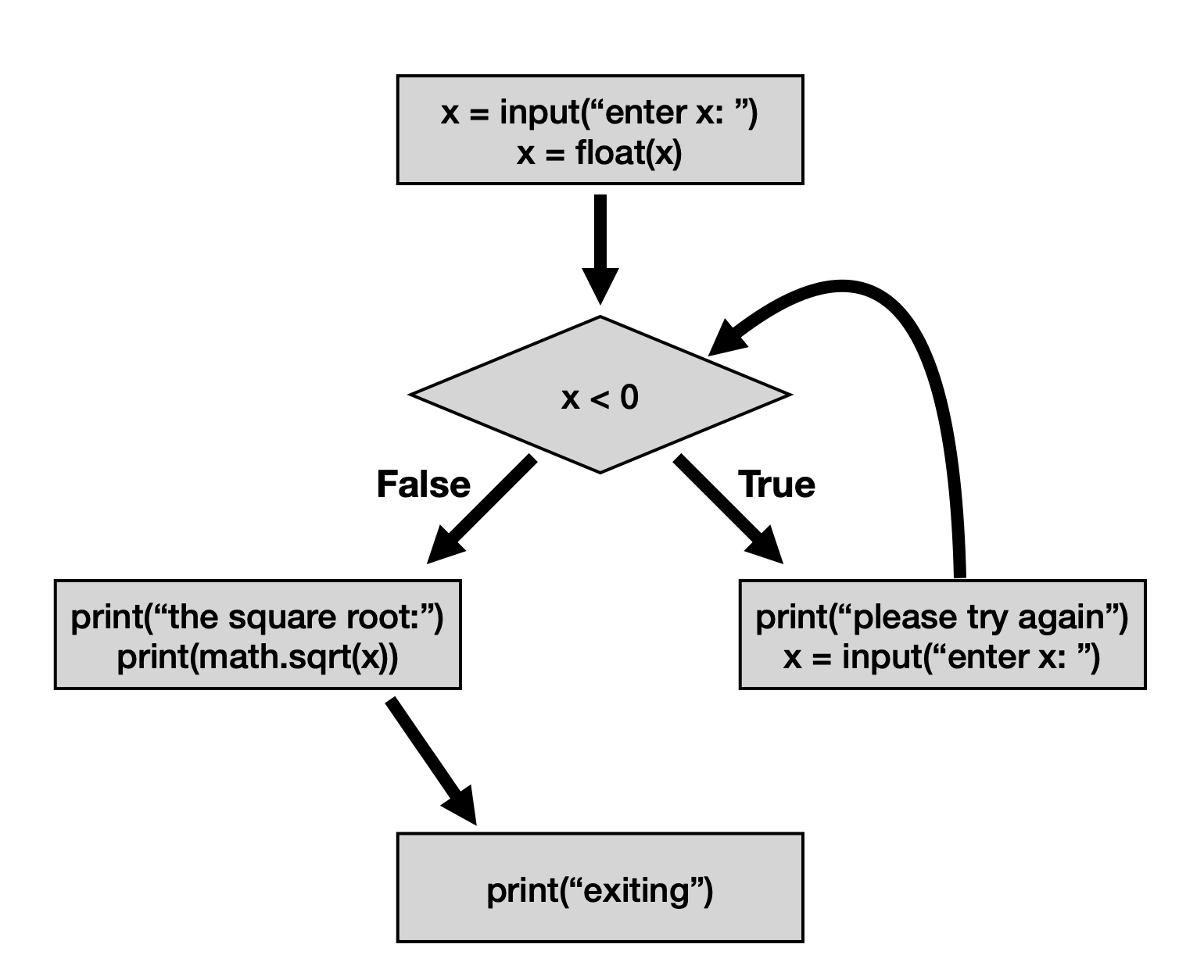
- basic code for a
whileloopwhile [condition]: # execute code - to repeat a loop
ntimes, either usei = 1andi <= nORi = 0andi < nbecause python starts counting from 0 and not 1 breakimmediately exits a loop, just like howreturnwill immediately exit a function- the keyword
continuewill stop the current iteration and checks the condition to begin the next iteration - loops can be nested
ch7: iteration
- reassignment is when an existing variable is updated to have a new value
- equality in python (and other languages) isn’t achieved through the
=operator, ex: sayinga = 3anda = bdoes not meanb = 3
- equality in python (and other languages) isn’t achieved through the
- an update is a specific type of reassignment where the new value is dependent on the old value
- increments are when a variable is updated by adding 1, decrements are when a variable is updated by subtracting 1
- a variable has to be initialized (it has to exist) before it can be updated
- repetition can be called iteration
whileloops will execute as long as the condition remains true after each iterationwhile n > 0: # while n is greater than 0, display and decrement n print(n) n = n - 1 print("Blastoff!")- an infinite loop is a loop that repeats forever, and occurs when there is no way for the condition to evaluate as false
breakstatements can be used to exit loops in the middle rather than at the beginning or end- an algorithm is a mechanical process for solving problems
sweigart ch2: flow control
todo
strings
- python can compare strings just like it can compare numbers with three edge cases: upper vs. lowercase, digits, prefixes
- uppercase always comes before lowercase, ex:
"Z"<"a" - numbers in string form aren’t actual numbers, they are still considered strings and digits are compared to each place, ex:
"100"<"15" - prefixes always come first, ex:
"bat"<"batman"
- uppercase always comes before lowercase, ex:
- the
isDigit()function returns if all the characters within a string are digits - a method is a special function that’s called on a variable or value, such as
isDigit()orupper(), while functions pass variables or values as parametersmsg = "hello" msg.isDigit() # method msg.upper() # method len(msg) # function - sequences are collections of ordered values, such as strings, lists, or tuples

- indexing a string is when you access a value of the string, while slicing is taking a chunk of a string
- each character in the string has its own index value which is the number to call to retrieve that character
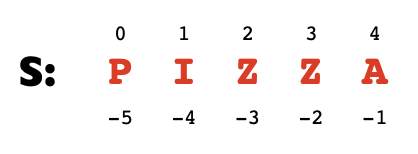
- each character in the string has its own index value which is the number to call to retrieve that character
- both
whileloops andforloops can be used to iterate through stringmsg = "hello" # while loop i = 0 while i < len(msg): letter = msg[i] print(letter) i += 1 # for loop for letter in msg: print(letter) forloops can also have a range which is a way of telling the computer how many times the loop should be executedfor i in range(5): # will iterate 0 to 4 print(i * 3) > 0 > 3 > 6 > 9 > 12
downey ch8: strings
- a string is a sequence
- the index is a value that corresponds to a character within a sequence, ex: my sequence is
"banana"and the value at index1is"a"(because python starts counting at 0)- the index has to be an integer value
len()is a builtin function that returns the number of characters in a string- negative indices can be used to count backwards from a string, where the
-1index returns the last character,-2index returns the second-to-last, etc forloops can be used to traverse through strings, also called for-each loopsfruit = "banana" for letter in fruit: # the loop iterates from 0 to 5 print(letter) > b # 0th index > a # 1st index > n # 2nd > a # 3 > n # 4 > a # 5- string segments are called slices which can be obtained using the
[n:m]operator where the operator includes thenletter but not themvalue, ex:fruit[1:4]would return"ana"- if the
nis omitted, the slice starts at the beginning and ends at themvalue, ex:fruit[:4]would return"bana" - if the
mis omitted, the slice starts at thenvalue and ends at the end of the string, exfruit[4:]would return"na" - a third argument can be used called step size which is the number of spaces between characters, ex:
fruit[0:5:2]would return"bnn"[start : end : step size]
- if the
- strings are immutable which means an existing string can’t be changed
- a counter is a variable in a loop that starts at 0 and increments each time a condition is met — sometimes the value of the counter is returned at the end of the loop
- an invocation is when a method is called on an object, such as the
upper()method, ex:fruit.upper()produces"BANANA" - the
find()method can return the index where a substring (or character) starts, but it can also take an argument for which index in the string it starts looking at, ex:fruit.find("na")produces2 - the
inoperator for strings returns a boolean value if the substring is present in the string, ex:"a" in "banana"returnsTrue - relational operators (
==,<,>) work on strings and are used to put words in alphabetical order, but all uppercase letters come before lowercase letters
downey ch9: case study: word play
- there is a built in function to read files —
open( [filepath] ) - to read lines of the file, use
readline(), which will read the next line of the file until it gets to the end of the file- sometimes the lines will end with whitespace characters such as
\r\nwhich we can get rid of by using thestrip()function after thereadline()function
- sometimes the lines will end with whitespace characters such as
- the process of reading a file can be made easier by using a
forloop - when testing programs, keep in mind special cases which are non-obvious cases that can produce errors, ex: what if a function is called on an empty string?
Program testing can be used to show the presence of bugs, but never to show their absence! —Edsger W. Dijkstra
state
lists
- a string is a sequence of characters — a list is a sequence of anything!
- we can index, slice, and put lists in
forloops and also use thelen()function, concatenate with the+operator, use theinoperator to find elements, and multiply by integers
- we can index, slice, and put lists in
# using len()
msg = "321go"
len(msg)
> 5
# concatenation
msg = "321go"
msg + "!!!"
> "321go!!!"
# using in
msg = "321go"
"g" in msg
> True
# multiply by int
msg = "321go"
msg * 3
> "321go321go321go"
# using len()
items = [99,11,77,55]
len(items)
> 4
# concatenation
items = [99,11,77,55]
items + [1,2,3]
> [99,11,77,55,1,2,3]
# using in
items = [99,11,77,55]
11 in items
> True
# multiply by int
items = [99,11,77,55]
items * 2
[99,11,77,55,99,11,77,55]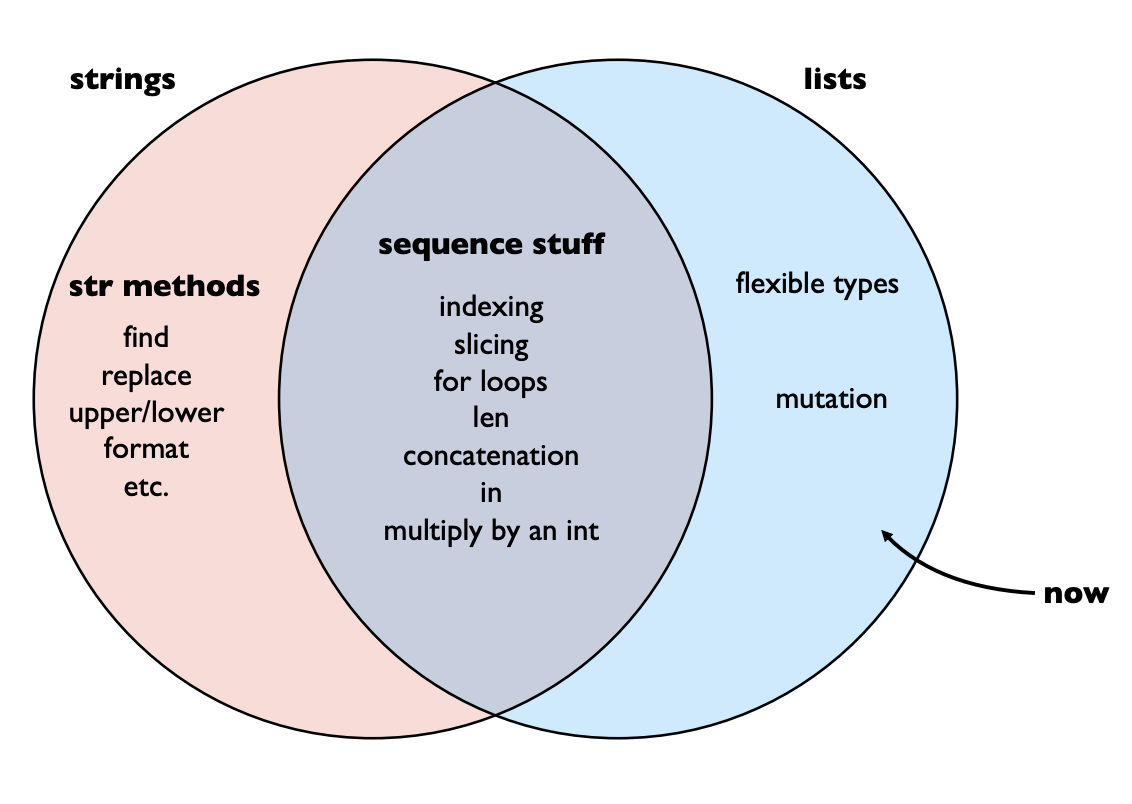
downey ch10: lists
- a list is a sequence
- elements of a list, called items, can be of any type (unlike strings, where they have to be characters) — they can even be different types than other elements within the same list
- to create a new list, use square brackets to enclose the elements, ex:
cheeses = ["Cheddar", "Gouda", "Mozzarella", "Swiss"] - lists within lists are called nested lists
- empty lists don’t contain elements and can be created using empty brackets, ex:
empty = [] - the bracket operator
[]can be used to access elements of a list (just like how brackets are used to access characters in a string), ex:cheeses[1] = "Gouda"- lists are mutable which means that elements in the list can be changed
- the
inoperator can be used on lists to find elements - when iterating through lists, the
inoperator will NOT update the elements in the list — to update the elements, you have to userange()andlen()cheeses = ["Cheddar", "Gouda", "Mozzarella", "Swiss"] for cheese in cheeses: # will NOT change the cheeses list cheese = "eaten" for i in range(len(cheese)): # WILL change the cheeses list cheese[i] = "eaten" - the
+operator will join lists while the*operator will repeat a list a given number of times - list slicing works the same way as strings — using the
[start : end : step size]operator, sections of lists can be isolated - since lists are mutable, a good programming practice is to make a copy of the list before modifying it
- list methods
append()adds a new item to the end of the listextend()takes a list as an argument and adds the entire list to the main listsort()arranges the list elements from low to highpop()removes and returns the final element in a list, or it can remove and return the item at a specified index- the
delkeyword accomplishes the same thing but without a return value
- the
remove()removes the item with the specified valuecheeses = ["Cheddar", "Gouda", "Mozzarella", "Swiss"] # the two statements below achieve the same purpose cheeses.pop(1) # used if you know the index cheeses.remove("Gouda") # used if you know the value
- special types of operators
- map alter every element in a sequence
- reduce simplifies a sequence of elements into a single value
- filter removes some elements and returns others, usually according to a user-given rule
- the
list()function breaks a string into a list of characters, ex:list(”hello”)returns['h', 'e', 'l', 'l', 'o'] - the
split()function breaks a string into a list of words- it can take a delimiter as an argument which is a specified boundary to split words
delimiter = "-" str = "spam-spam-spam" str.split(delimiter) # produces ["spam", "spam", "spam"]
- it can take a delimiter as an argument which is a specified boundary to split words
- the
join()function joins a list into a string - two lists can be equivalent, meaning they have the same elements, but not identical, because they are referring to two different objects
- identical → equivalent, but equivalent does not mean identical
- a variable assigned to an object is called a reference, and when an object has more than one reference, that means it is aliased
- if the aliased object is mutable, then any change will affect all aliases of the object
- some operations (
append(),split(),[::]) modify lists, while other operations (+,*) create new lists
CSV tables
- CSVs organize cells of data into rows and columns
- only holds strings and all text is plaintext
- delimiters are characters that act as separators between objects — for CSVs, the delimiter is a comma
- when a CSV is opened in python, its result is a list of lists (or like a 2D array)
sweigart ch16: working with CSV files and JSON data
- CSV, comma-separated values, are simplified spreadsheets stored as plaintext — supported by many types of programs and is very simple, exactly as advertised
- each row in a CSV file represents a row in a spreadsheet, and each comma represents the next column
- the
csvmodule has areaderobject which helps the user read the CSV fileimport csv exampleFile = open("example.csv") # open the file exampleReader = csv.reader(exampleFile) # "reads" the file and returns a reader object exampleData = list(exampleReader) # converting data into list exampleData[0][0] # data at row 0, col 0 exampleData[0][1] # data at row 0, col 1- for larger CSV files, use a
forloop and load one row at a timefor row in exampleReader: # iterating through reader object str(row) # execute code
- for larger CSV files, use a
dictionaries
- a data structure is a collection of data values, their relationships, and the operations that can be applied to the data
- maps associate values with labels and use labels to lookup values
- lists are maps which associate indices with values
- dictionaries map labels (keys, not indices) to values — keys must be immutable
nums_dict = {"first":900, "second":700, "third":800} nums_dict["third"] # accessing 800 - reminder on parenthetical characters
- parentheses
(): specifying order, calling functions - brackets
[]: creating lists, indexing, slicing, dictionary lookups - braces
{}: creating dictionaries, creating sets
- parentheses
- use the
pop()method to delete elements in the dictionary — by default,pop()accepts keys - to add elements, assign keys to values using brackets like
d[20] = "twenty" - create an empty dictionary
d = {}ord = dict() - the
inoperator only checks if keys are present in the dictionary, it does not check for values - keys and values can be extracted and turned into lists using
list(d.keys())orlist(d.values()) - use
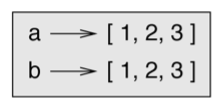
get()to return values,pop()to delete values in a dictionary and specify a default value if the key doesn’t exist - bucketing/binning: dictionary of lists
- table representation: list of dictionaries
- probability tables/Markov chains: dictionary of dictionaries

downey ch11: dictionaries
- dictionaries have keys and values which make up items — each key is mapped to a value
- create a new dictionary using the
dict()function or two curly brackets{}- add elements to a dictionary by using square brackets and assigning a value, ex:
nums["1"] = "one"wherenumsis the dictionary,"1"is the key, and"one"is the value
- add elements to a dictionary by using square brackets and assigning a value, ex:
- dictionaries are not ordered — the only thing that matters is the key-value pairs stay the same
- the
values()method returns a collection of all the values - the
inoperator,len()function, andsorted()function all work on dictionaries - the
get()method returns the corresponding value associated with a key — if there is no value then it returns a default value - a list can be a value in a dictionary, in other words, a list can be a value that is assigned to a key:value pair
- a list cannot be a key because the keys need to be hashable
- a singleton is a list that contains a single element
- a hash is a special function that takes values of any kind and returns and integer
- dictionaries use the integers (called hash values) to store key:value pairs
- hashes only work if the object is immutable (and lists aren’t immutable)
- a memo is a dictionary that can be used to keep track of values that are already known
- when calculating the Fibonacci sequence, a memo can be used to store values that were already calculated
- variables created outside functions are called global variables because they are located in the
__main__frame - flags, boolean values for conditions, are usually global variables
- have to be declared within functions before they can be changed, ex:
global is_calledbefore usingis_called = !is_called
- have to be declared within functions before they can be changed, ex:
JSON
- CSVs are good at storing list of lists, JSONs are good at storing dict of dicts
sweigart ch16: working with CSV files and JSON data
- JSON, JavaScript Object Notation, stores information as JavaScript source code in plaintext files
- application programming interface (API) is a way to bridge programs with their applications
- lets you scrape raw data from the website
- the
jsonmodule handles all the stuff between JSON data and python values usingjson.loads()andjson.dumps()functions- data can be read with the
loads()function which will return the data as a dictionary - data can be written with the
dumps()function which can only take dictionary, list, int, float, string, Boolean, orNonedata types and will translate it into JSON data
- data can be read with the
objects
- using parentheses instead of brackets will create a tuple instead of a list
- like a list,
forloops, indexing, slicing can be done
- like a list,
- the
namedtupleobject can be imported and it will allow new types to be createdfrom collections import namedtuple Person = namedtuple("Person", ["fname", "lname", "age"]) people = [ Person("Alice", "Anderson", 30) Person("Bob", "Baker", 31) ] p = people[0] print("Hello " + p.fname + " " + p.lname) > Hello Alice Anderson - the mutable equivalent of a
namedtupleis called arecordclass, ie: variables can be changed after they have been assigned - python uses separate references and objects because: 1) performance; 2) centralized updates
- the
isoperator will returnTruewhen two references point to the same object, while the==operator only checks if the two objects are equivalent
downey ch10: lists
- the
isoperator can tell you if two objects are equivalent and identical - identical implies equivalent, but equivalent does not imply identical
downey ch12: tuples
- a tuple (too-ple) is an immutable list usually enclosed in parentheses — create an empty one using
tuple()- can also refer to a group of objects in general
- the bracket operator (for indexing) and slice operator
[::]work on tuples - for relational operators (
<,>,=) work by comparing each element of the tuple until there is a difference, and subsequent elements are not considered(0, 1, 2) < (0, 3, 4)(0, 1, 2000000) < (0, 3, 4)
- tuples can be assigned in a special way
a, b = b, a # tuple of variables on the left # tuple of expressions on the right- the number of variables on the left side has to be equal to the number of expressions on the right side
addr = "[email protected]" uname, domain = addr.split("@")
- the number of variables on the left side has to be equal to the number of expressions on the right side
- a parameter that begins with
*will gather all arguments into a tupledef printall(*args): print(args) printall(1, 2.0, "3") # combines all arguments into tuple - an argument that uses the
*operator on a tuple will break the tuple (scatter) into multiple arguments (so the opposite of a gather)t = (7, 3) divmod(*t) # breaks t into 2 arguments - the
zip()function takes multiple sequences and returns a list of tuples where each tuple has an element from each sequence- the zip object is an iterator which means that it’s an object that iterates (moves through) a sequence — usually has a
.next()and no indices
s = "abc" t = [0, 1, 2] zip(s,t) # creates a zip object for pair in zip(s,t): print(pair) > ("a", 0) > ("b", 1) > ("c", 2)- if the sequences are different lengths, the zip object ends when the first sequence ends
- this is very useful for traversing through multiple sequences at the same time
- the zip object is an iterator which means that it’s an object that iterates (moves through) a sequence — usually has a
- the
enumerate()function creates an enumerate object, or a sequence of pairs matching an index to an element in the argumentfor index, element in enumerate("abc"): print(index, element) > 0 a > 1 b > 2 c - dictionaries have a method called
items()that returns a sequence of tuples of key:value pairs - a list of tuples can be initialized into a new dictionary using
dict() - tuples are commonly used as keys in dictionaries because lists can’t be used as dictionaries (tuples are immutable, lists are not)
copying
- slicing creates a new object
- three levels of copying
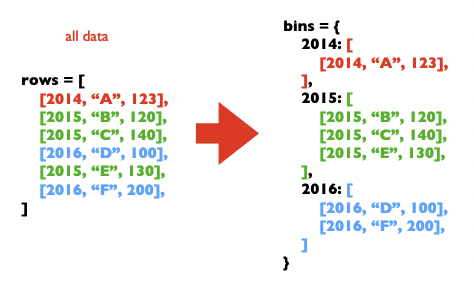
- reference copy (0 levels): fastest but most dangerous, only creates a pointer to the object — any changes to either object will change both
- shallow copy (1 level): used to copy an object (ie, a list) so the original doesn’t get corrupted, but it only makes a new object (a new list) that refers to the same original objects
- helpful for reorganizing object positions like sorting a list or dictionary, but not helpful if you want to change values
- helpful for reorganizing object positions like sorting a list or dictionary, but not helpful if you want to change values
- deep copy (all levels): slowest but the safest, copies everything including sub-lists and sub-dictionaries — any changes made in the copy is not reflected in the original
sweigart ch4: lists
- when assigning lists to variables, a reference to the list is what’s stored, not the actual list itself
- so if two variables point to the same list, then any change made on one variable will reflect on the other
- python uses references when storing values of mutable types, like lists or dictionaries; it will store actual values for immutable types like strings, ints, or tuples
- even though lists and dictionaries are passed by reference through functions, they will still be altered directly
- the
copymodule provides acopy()anddeepcopy()function that makes duplicate copies of dictionaries or lists (and not just references)- if the copy contains lists, use
deepcopy()because it will copy inner lists
- if the copy contains lists, use
recursive functions
- a tree is an example of recursion where there are recursive cases (branches) and base cases (leaves)
- a recursive function calls itself, directly or indirectly
- both iteration and recursion achieve the same purpose but often one is more efficient or easier to implement than the other
- an example using factorials
def fact(n): if n == 1: return 1 p = fact(n-1) return n*p - variables exist in a frame, which are stored in stacks — only the topmost frame is active at a time
downey ch5: conditions and recursion
- a function that calls itself is a recursive function and executing that function is called recursion
- a base case is the last call of the recursive function and it does not make another call
- if a recursion never reaches a base case, then it’s an infinite recursion and the program will never end
downey ch6: fruitful functions
- return values are passed back up the recursion stack
- an example with the Fibonacci sequence
def fibonacci(n): if n == 0: return 0 if n == 1: return 1 else: return fibonacci(n-1) + fibonacci(n-2) # calls itself - sometimes the the function can miss the base case and keep recursing, so it’s good practice to make sure the input to the function is legal
- a guardian is a chunk of code that protects the code from executing on the wrong arguments
function references
- functions are objects, so they behave like objects
- can be referenced by variables, lists, or dictionaries; pass function references to other functions
- if two different variables are assigned to a function, then both variables can call the function
def f(): return "hi" g = f f() # returns "hi" g() # also returns "hi" - function invocations have parentheses, function references do not
- method references can be passed through parameters if the module name is used in the function invocation like, ex:
str.upper(val)does the same thing asval.upper()but usingf = str.upper, we can callf(val) - the
sorted()function has akeyparameter that allows you to choose what to sort the items by, and thekeycan be a function referenceattrgetteris for namedtuples,itemgetteris for lists(?)
generator functions
- for recursive functions, make sure the arguments are changing and will at some point hit the base case
- an eager function will finish execution before returning the end value, whereas a lazy function returns a value at each step and needs to be prompted to return the next value
- a generator can stop and return a value and then execute more code after
- use the
yieldkeyword
def f(): yield 1 yield 2 yield 3 for val in f(): print(val) # printed once every loop > 1 # goes back to executed yield 2 > 2 > 3 - use the
- multiple instances of the same generator can be executing at the same time
- the
next()function is built for generator objects and it will iterate through a generators- by default, generator objects (from yield statements in functions) will create generator instances which can be used by
next()… I think…
- by default, generator objects (from yield statements in functions) will create generator instances which can be used by
- an iterable is something that can be iterated over, such as sequences like list, tuple, ranges, or
dict.keys()ordict.values()- an iterator object is an iterable object and can be created for any iterable object — it’s a special object with the
next()function
- an iterator object is an iterable object and can be created for any iterable object — it’s a special object with the
- is
iter(x)works, thenxis iterable; ifnext(x)works, thenxis an iterator
error handling
- turn semantic errors into runtime errors
- a string can be formatted using brackets and
.format()"area={:.2f}".format(2.29834)will print to2.29(CHECK)
- anything that can be used in a boolean statement can also be used in an assertion which will throw an error and end the program if it’s false
- the
tryandexceptblocks let you run code even after it crashes — any errors thrown in thetryblock will prompt theexceptblock to run- when an error occurs in a
tryblock, the program tries to find the closestexceptblock to execute — python will exit functions or loops until it can raise the exception
- when an error occurs in a
- specific exceptions can be specified using
Exceptionobjectstry: print(1/0) # buggy code except Exception as e: print("An exception was raised: " + str(e) + " " + type(e))- it’s good practice to get very specific about exceptions so the user knows what went wrong
- to crash the program manually, raise an exception with
raise [Exception]("error message")— the program will search for anexceptclause
sweigart ch10: debugging
- python raises exceptions when the code is wrong but exceptions can also be manually raised using
raise Exception("error message") - tracebacks can tell you which line the error appeared on
- there is a
tracebackmodule that allows you to manually deal with bugs and output them to log files, which means the program will keep running even if exceptions are thrown in the background - an assertion is a sanity check to make sure the code is doing what it’s supposed to do, ex:
assert [condition], "[error message]"- if an assertion fails, the error message is displayed and an
AssertionErroris thrown
- if an assertion fails, the error message is displayed and an
data science
files and directories
f = open("path")will open a file and allow you to read from and write tof- always close your files after using them!
- to read a file, either use
read()to return the entire file content into a string,next()to get one line of the file at a time, orlist()to turn the file contents into a list - the
write()function allows you to write to a file - the
os.path.join()function will join parts of a path together — this is useful because different OS use different forward and backward slashes and this function allows your code to run on multiple platforms - encoding is taking data and making it readable to the computer, while decoding is taking computer-language and making it readable to a human
- the best way to parse data from large files is to use a generator to turn the data into a stream
- using
with open("path") as f:will accomplish the same thing as just usingopen()but it’s faster (because whole data isn’t moved into memory) and the closing clause isn’t required json.dump("file", [file object])is the equivalent ofjson.dumps("file")andf.write()data = json.load(f)is the equivalent off.read()andjson.loads()os.path.basename(path)names the file at the end of the path
downey ch14: files
- persistent programs run all the time and permanently store some of their data — this includes OS and web servers
- to write to a file, it has to be opened in “write mode” using
open("file path", "w") - the format operator is
%and is preceded by a format sequence, ex"%d"is the sequence to format an argument as a decimal integer within the stringcamels = 42 print("I have spotted %d camels." % camels) > "I have spotted 42 camels."- there is also
"%g"for floating-point numbers and“%s”for strings - the number of format sequences must match the number of arguments that come after the format operator
- there is also
- directories are also called folders
- a relative path specifies where a file is located with respect to the “current working directory”, while an absolute path specifies how to get to a file from the root of the entire system
- the
osmodule (stands for “operating system”) includes functions for working with files and directories —os.path.abspath()to find absolute path,os.path.exists()to check if a file or directory exists, etc… - a database is like a permanent dictionary that organizes data — python offers the
dbmmodule to work with databases- each item in the database has an associated bytes object
- the
picklemodule translates any object into a string to be stored in a database
- any program that can be launched from the shell, can also be launched from within python using a pipe object
- any file with python code in it can be imported as a module
pandas
- tabular data is data that is organized with tables and columns — using the
pandasmodule to order this data is much easier than using lists- Pandas tables are built using
Serieswhich is a special data structure
- Pandas tables are built using
- pandas terminology
- integer position is a label like 0, 1, 2, that is equivalent to a list’s index
- index is equivalent to a dict’s key
- lookup values using indices (keys)
.loc["key"]or lookup by integer positions (index).iloc["index"]’- negative indexing isn’t supported by Series
- new slices are not indexed from 0
- operations on Series work like vector math — the operation is applied to every element
nums = Series([100, 200, 300]) nums + 1 # adds one to every element Series([1,2,3]) * 3 # multiples all elements by three Series([10,20]) + Series([3,4]) # results in Series([13, 24])- comparisons can also be done (
%,>,==)
- comparisons can also be done (
- boolean indexing is where you take every value in a Series that matches to
Truein a boolean Series, also called “fancy indexing”letters = Series(["A", "B", "C", "D"]) bool_series = Series([True, True, False, False)] letters[bool_series] > 0 A > 1 B letters[Series([False, True, False, True]) > 1 B > 3 D - example combining operations and fancy indexing
S = Series([1,9,2,3,8]) B = S > 5 # Series that evaluates to True at any index where S>5 S[B] # filtering out values in S > 1 9 > 4 8 - use and
&, or|, not~when chaining multiple conditionals for fancy indexing - a
DataFrameis a table of aligned Series - calling a comparison function will compare Series even if the indices are mismatched (keys/indices are arranged wrong) —
gt(),eq(),ge(),le()… - a DataFrame is made up of a dictionary of Series but it could be a dict of lists, a list of lists, dict of dicts, list of dicts
- the indices can be specified when creating a DataFrame, ex:
DataFrame({data}, index=["row titles"])
- the indices can be specified when creating a DataFrame, ex:
- to access a single cell in a DataFrame, use
loc[row,col] - to read a CSV file, use
pd.read("file path")which will automatically add it as a DataFrame
web
- manual downloading is tedious; datasets are difficult to download in complete
- every machine has an IP address and requests are sent between IPs but nicknames (domains) are easier to remember and are often used in place of IPs
- ports are specific locations on the ends of IP addresses
- domain: which computer; port number: which program; file name: which data
- a URL puts together all elements of a request to a machine, ex:
https://en.wikipedia.org:443/wiki/URL GETspecifies that we want to get data from the remote server;POSTmeans we are uploading data to the server- status codes
- 200 is good
- 404 is the file isn’t available (file not found)
- 500 is a server error
- all data parsed from webpage is formatted in a single string (I think)
- the shortcut to turn a .json file into a dict is
[requests.get('url')].json
- the shortcut to turn a .json file into a dict is
- hypertext is text that is clickable links
- browser sends a URL (domain, port, file) HTTP request
- HTML stuff
- tags
<b>,i,u…, allow you to group pieces of content together and apply special effects - hyperlinks:
<a href="[link]"></a> - images:
<img src="source"> - tables:
<table>, rows<tr>, cell<td>
- tags
- python can convert to html by outputting (
open(html_path, “w”)) to a .html file- each tag has to be written to the file… it’s not like .csi files in java where the code is mixed
- BeautifulSoup allows for searching within HTML files
- the browser takes HTML and generates a DOM (Document Object Model) Tree
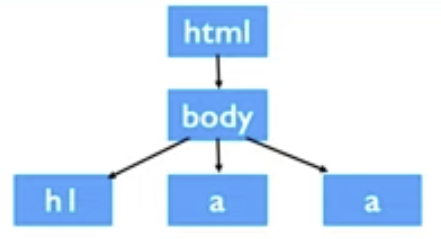
- BeautifulSoup creates a new DOM object when using
BeautifulSoup([data], [parser])- the
find_all()function will return a list of all elements with that tag —find()returns the first instance - once the elements are found, use the
get_text()function which will parse the text within those elements
- the
- if there are nested tags within an element, use the
.childrenattribute which will return a list of the children tags of the parent element - most websites have a
robots.txtfile which will tell you what’s allowed and disallowed when “crawling” (pulling data from) in their site
sweigart ch11: web scraping
- web scraping is downloading and processing content from the web
- the
requestsmodule lets you download files from the web (has to be install from cmd)requests.get()returns a Response objectraise_for_status()checks for if the request went through — will produce errors like 404 not found, etc
- save and write the web page to a file
res = requests.get('https://automatetheboringstuff.com/files/rj.txt') res.raise_for_status() playFile = open('RomeoAndJuliet.txt', 'wb') for chunk in res.iter_content(100000): # chunks in bytes playFile.write(chunk) playFile.close() - the Beautiful Soup (bs4) module parses HTML files in the drive
- why is web parsing and pandas more tedious to read than the entire two units of this course combined? this is an absolute slog and idk what’s going on even
exampleSoup = bs4.BeautifulSoup(open("example file"))- the
select()method will parse specific CSS syntax, ex:soup.select("div")will find all elements named<div>
- the
seleniummodule can directly control the browser by clicking links and filling in login information - the shortcut of performing an action to every element in a list is
new_list = [action for x in old_list]— called list comprehension - defaultdict is a dict object that gives a default value to a key if it doesn’t exist in the dict yet
databases
- SQL databases are collections of named tables where all columns have an enforced type — CSV files are just one table of strings
- can keep multiple copies of the same data stored in different ways to make retrieval efficient
- SQL (structured query language) servers include Oracle, MySQL, SQLite
sqlite3.connect(filepath)is basically opening the file and will return a Connection object- use pandas to read everything in the db
pd.read_sql("SELECT * FROM sqlite_master", [connection obj])and save it into a DataFrame to parse
- use pandas to read everything in the db
- SQL has different type names:
INTEGER,REAL(float),TEXT(str) CREATE TABLEsignifies new table and will be followed by the table name- to get data and narrow down to to specific cells, start with
SELECT [ ] FROM [table name];and follow in the order belowSELECTwhich columnsFROMwhich tableWHEREwhich rows; filtering in the original tableGROUP BYgroups into categories (buckets)HAVINGwhich rows, filters from the sorted groups aboveORDER BYsorts the data —ASCascending,DESCdescendingLIMIThow many rows
- the
ASkeyword creates a new column and can be used later - aggregate queries
COUNT()counts the number of items in a col- use
DISTINCTto remove duplicates
- use
SUM()adds entire col togetherAVG()averages a col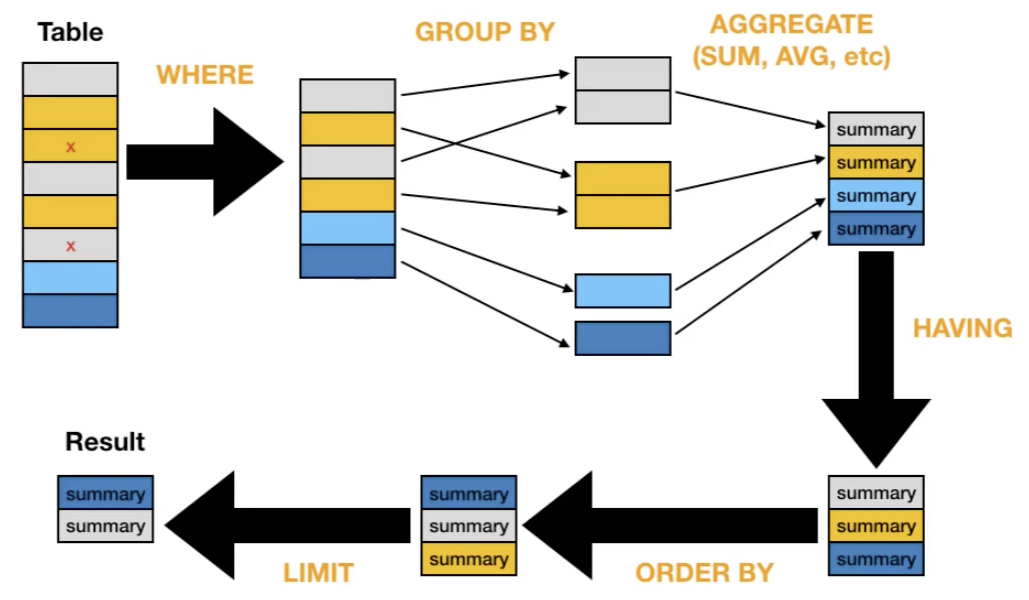
plotting
- pandas Series and DataFrames integrates with matplotlib
[Series].plot.pie(figsize=(width, height), color="")makes a pie chart out of a Series[s,df].plot.bar()makes a bar plot- the Series object can be directly altered before it’s plotted, ex:
([Series] / 100).plot.bar()will divide all elements in the Series by 100 and plot accordingly - the DataFrame bar plot takes a parameter
stacked=which will make a stacked bar plot
- the Series object can be directly altered before it’s plotted, ex:
[DataFrame].plot.scatter(x="", y="")makes a scatter plot out of a DataFrames=size of the pointsc=color of the pointsvmintakes a floating-point value that restricts the b/w of the plot points…
marker=shape of the points"o""+""^""v"- set the limits of x and y axes using
xlim=andylim=
[s,df].plot.line()line plot for Series or DataFrame- the index is the x-axis unless otherwise specified
- for Series, use
s.sort_index()
- for Series, use
- the index is the x-axis unless otherwise specified
- change default plot settings (like font size) by calling
matplotlib.rcParams["setting"] - once a plot is made, it returns an AxesSubplot object which can be tweaked
plot.set_title("title")plot.set_ylabel("label")plot.set_xticklabels(list([Series].index), rotation=)sets the orientation of the x-axis labelsplot.splines[”right”, “top”, “bottom”, “left”].set_visible[True, False]- splines are the edges of the graph
- it’s good practice to make a function that makes your plots look the same
- the main plot can be divided into subplots which you can specify settings for
fig, ax = plt.subplots()and then customize the axis
- set the index of a DataFrame using
[DataFrame].set_index()to have custom tick labels- tick positions also need to be set with
[df.plot.line()].set_xticks([list])
- tick positions also need to be set with
- define a custom header of a DataFrame using the
name=parameter - to make a scatter plot for multiple classes, you have to loop over each class while plotting on the same
AxesSubplot- define a list of colors to change colors as you loop through classes
colors = [] - add a legend using
label=and the title of the class
- define a list of colors to change colors as you loop through classes
- use
cumprod()to find the cumulative product - with large amounts of data, only present the important percentiles (using
.quantile(percentile=, axis=[column]))and not the whole set of data - drop NaN values using
dropna() - verify that data points aren’t being cut off in a plot using
assertstatements to comparexlimandylimwith the max values of x and y axes- ex:
assert [df[axis]].max() <= [ax].get_xlim()[?]0 or 1…?
- ex:
- log base 10 refocuses into how long the number is (how many 0s) instead of digits — logarithmic scale is used so small values aren’t “brushed aside” when plotting
plot.subplots()can take a parameterncols=andnrows=which will create multiple AxesSubplot objects- to ensure the same y-axis across multiple graphs, use the parameter
sharey=True
- to ensure the same y-axis across multiple graphs, use the parameter
randomness
random.choice([list])returns a random value from the list (using therandommodule) — sampling with replacementrandom.choices([list], size=)returnssizerandom values —sizecan also be a tuple to generate multidimensional arrows (row, col)- takes a parameter
p=where the probability can be predetermined
- how do we know if something is really random? look at a large sample size
- seeds are predetermined random sequences … like Minecraft
- it’s easier to debug errors that depend on randomness if the randomness can be controlled through seeds
- large difference in a small data set, or a small difference in a large data set means it might not be random