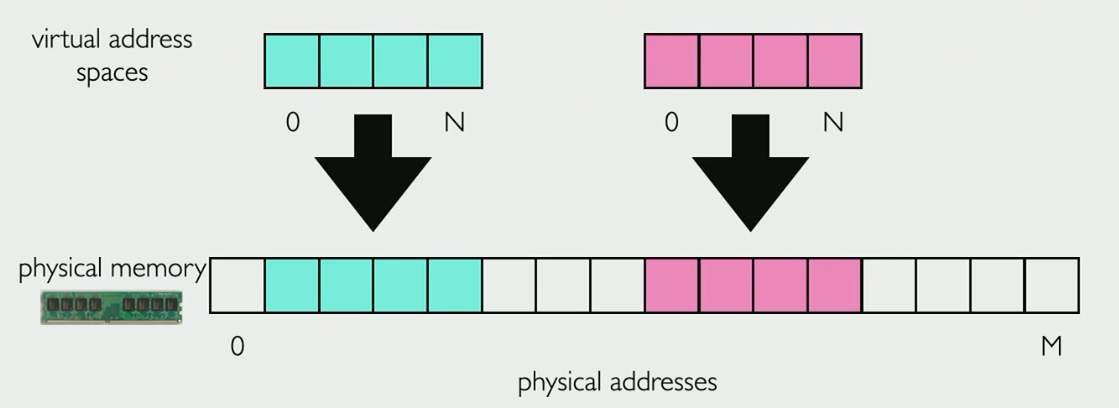
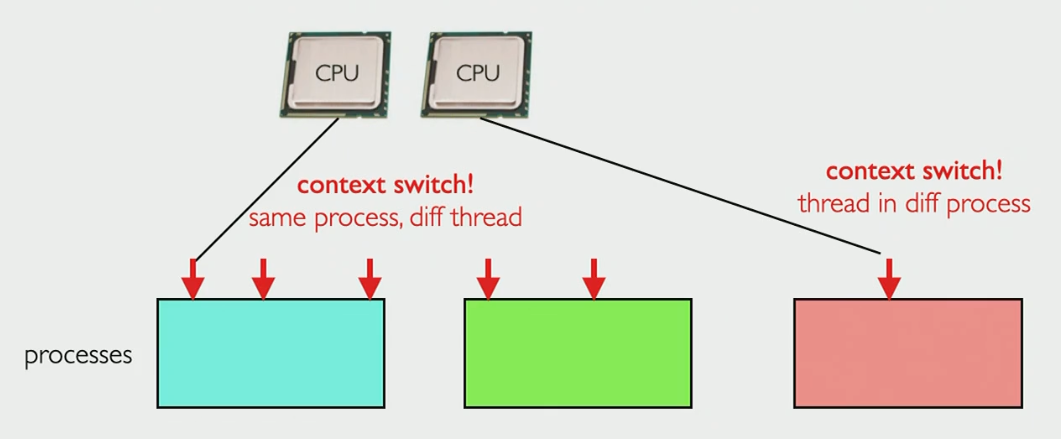
Virtualization is the idea that processes are given private resources such as memory or hardware
One example is virtual address spaces which are chunks of memory in a larger block of memory, another example is a VM
Docker is a way of creating lightweight virtual operating systems, which are called containers
The purpose of containers / VMs are to create sandboxes which can run code in an isolated environment
For example, running malicious code in a sandbox will not affect anything outside of the sandbox
Docker image: a snapshot of a container
Containers can be created on your VM from an image
Dockerfiles set up environments
Dockerfiles will cache intermediate progress, so it’s good practice to put stuff that’s stable at the top, and stuff that’s constantly changing near the bottom of the Dockerfile
Use docker run -it IMAGE_NAME bash to get an interactive terminal to run inside a docker container
Use docker run IMAGE_NAME sh -c "COMMAND" to run a command inside an image without going into the image
There is latency when loading data from RAM into CPU, the solution to this is the cache “hot” data
Caching is a resource tradeoff — if I cache a file, I avoid rereading from storage, but I’m using up memory
What do we cache? Data/webpages that we need to access repeatedly
When do we cache? The first time we read something, it is added to the cache
When do we remove (evict) from the cache? Depends, there are several policies
Why do we evict? Limited cache space
Random: remove cache entry at random
FIFO (first in, first out): remove whatever has been in the cache the longest
LRU (least recently used): remove the cache item that was accessed the longest ago
FIFO and LRU are bad when you need to keep scanning the same data repeatedly because you can have a situation where you evict the values that you need next
Cache size = 4, Data = [1,2,3,4,5,1,2,3,4,5], then the hit rate is 0%
Avg latency = (hit% * hit latency) + (miss% + miss latency)
Gradient is the slope at a particular location (in a function)
Stochastic gradient descent: optimization using slopes
x = torch.tensor(0.0, requires_grad=True) # init at x = 0.0optimizer = torch.optim.SGD([x], lr=0.01) # optimize x values with learning rate 0.01for epoch in range(5): y = f(x) # apply f to get new y value y.backward() # figuring out gradient wrt y -> y/x optimizer.step() # makes a change to variables based on gradient and learning rate optimizer.zero_grad() # resets gradient to 0 because `.step()` adds to the current gradient value
Learning rate is hard to optimize — too big and you will miss the target, too small and it will take too long to solve
Randomly split into train, validation, and test data sets
Why might a model score worse on test data than on validation data? Because we chose the model that fits the best to the validation set.
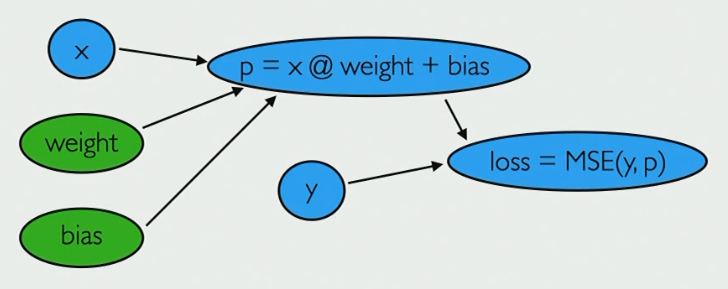
Deep learning uses models that are deeply nested functions
y=model(x)=LN(R(LN−1(R(⋯(L1(x))))))
Each Lk(x) stands for a model represented by Lk(x)=xW+b while R stands for a function like sigmoid or ReLU
PyTorch helps us track computations through DAGs
Loss (Mean Squared Error) depends on a lot of things, so loss is what we try to optimize
Stochastic gradient descent is doing gradient descent in shuffled batches so that we can minimize issues with not enough RAM
The df.pivot function can reformat tables!
To use PyTorch for ML, we want to have a DataSet (ds) and a DataLoader (dl)
The DataSet is a clean, raw representation of the data that we are using
The DataLoader basically helps enumerate and access the DataSet
Can help with creating batches and shuffling
basic training loop
model = torch.nn.Linear(1, 1)optimizer = torch.optim.SGD([model.weight, model.bias], lr=0.00001)loss_fn = torch.nn.MSELoss()for epoch in range(50): for batchx, batchy in dl: predictedy = model(batchx) loss = loss_fn(batchy, predictedy) loss.backward() # update weight.grad and bias.grad optimizer.step() # update weight and bias based on gradients optimizer.zero_grad() # weight.grad = 0 and bias.grad = 0 # how well are we doing? x, y = ds[:] print(epoch, loss_fn(y, model(x)))
Block devices are long term storage devices that are accessed in units of blocks
Caching is for storing data that might be accessed later, buffers mostly pertain to minimizing function calls for the same data, storing one large block/page of data when lines are being read one at a time
Small reads (<4KB):
No good way to read only one column without also reading everything else
The whole block has to be accessed to get a small portion of data
Hard disk drives (HDDs):
Steps to transfer data:
Move pointer to correct track
Wait for disk to rotate until data is under head
Transfer data
For transferring small amounts of data, then the first two steps will dominate the processing time
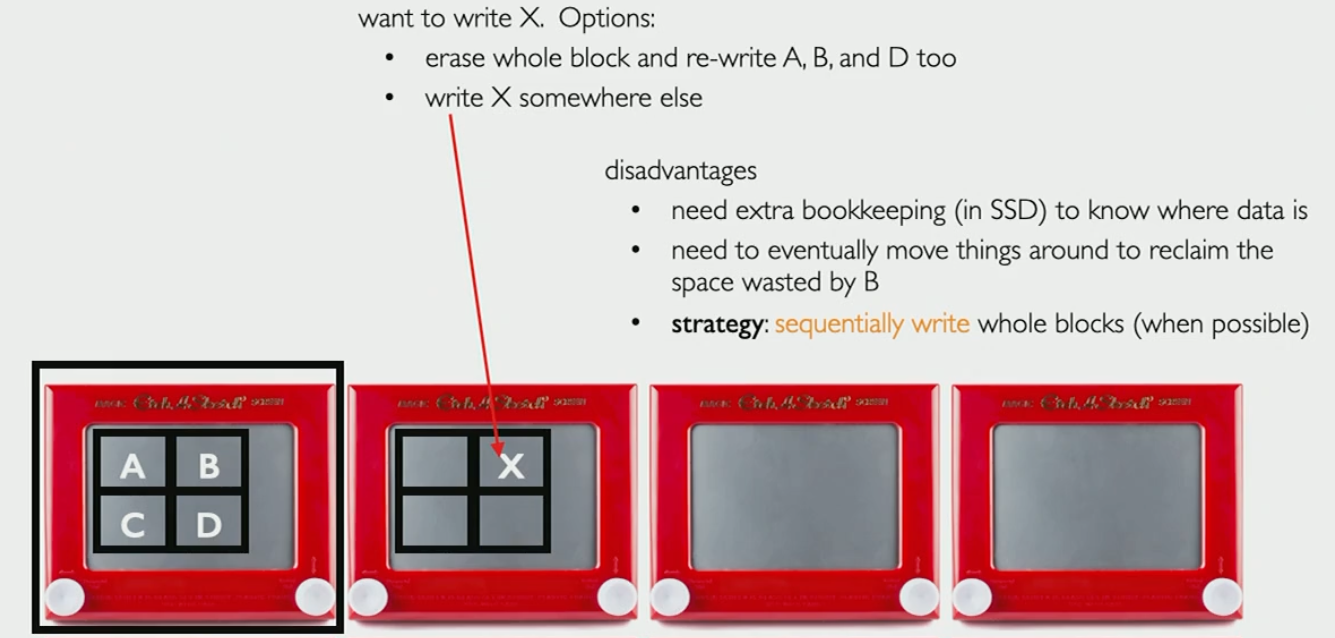
Solution: assign sequential block numbers for HDDs
Solid state drives (SSDs):
No moving parts and can read data in parallel
Blocks and pages are used in different context than HDDs
Erase content in blocks, write content in pages, but can’t rewrite to individual pages
To rewrite content, SSDs just put it somewhere else and it needs to be tracked
Block devices can be divided into partitions
Redundant Array of Inexpensive Disks (RAID) controllers can make multiple devices look like one device
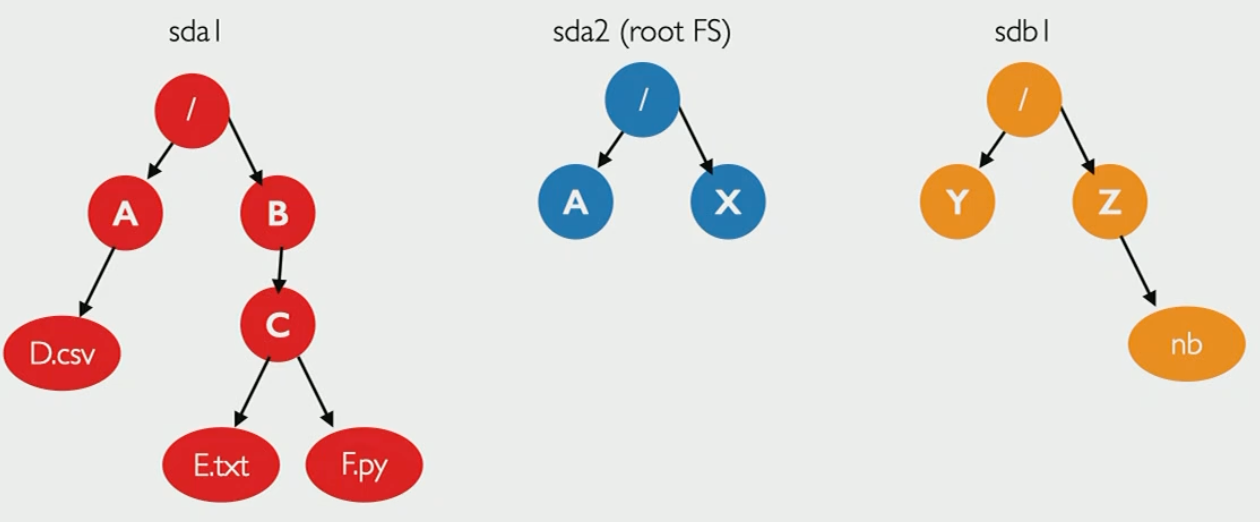
Local file systems can track files by segmenting them into blocks and tracking which blocks are relevant to the file — this is called an inode structure
Directories contain inode mappings and names of files